2024年2月16日、ChatGPTなどを世界に発信しているOpenAI社から非常に大きな発表がありました。
それが、
Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions. https://t.co/7j2JN27M3W
Prompt: “Beautiful, snowy… pic.twitter.com/ruTEWn87vf
— OpenAI (@OpenAI) February 15, 2024
動画生成AI「Sora」が完成しました!
という衝撃の内容でした。
もちろん動画生成AIは徐々に出来てきてはいましたが、ある程度のクオリティが保たれた動画生成AIは、これだけ生成AIが進んできた現代でももう少し掛かるのでは?、なんて言われていましたが、2024年初頭にもう出来てしまっているようでした。
今回はSoraの概要について見ていきながら、今後の活用方法などについても考えていきたいと思います。
概要

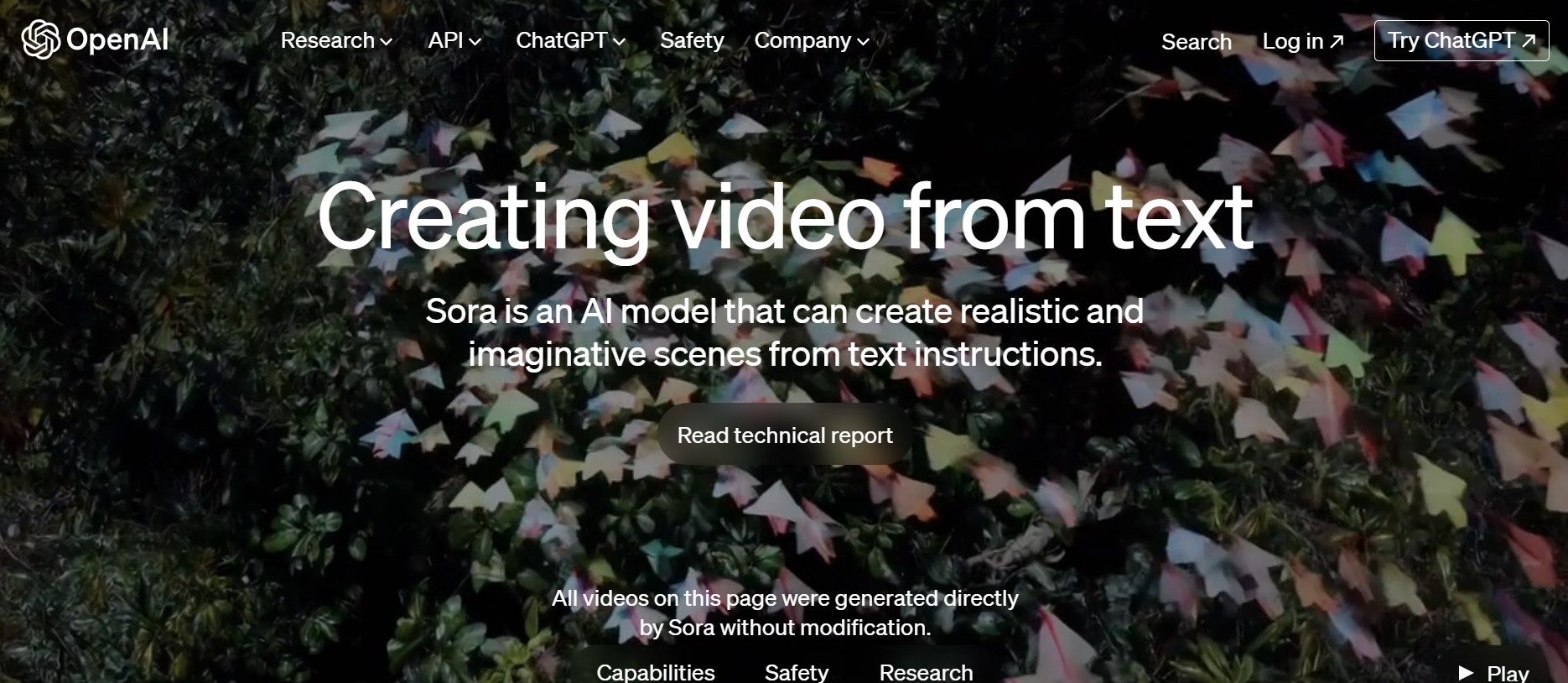
今回OpenAIが新たな生成AIモデル「Sora(ソラ)」を発表しました。
これは、テキストプロンプトから最長1分の動画を作ることができる革新的なシステムです。
詳細なシーンや複雑なカメラワーク、キャラクターの感情表現に長けていますが、リリース日は24年2月現在ではまだ未定のようです。
現在は安全対策を含むテストを重ねており、物理的な挙動や詳細の描写には若干の課題もあるようです。
OpenAIは映画やその他映像、クリエイティブな業界から著作権の訴訟なども受けているため、その対策も現在行っているようです。有識者や教育者と連携して、プライバシーに関する内容などの管理機能を含む新たなAI技術の開発にも力を入れているようで、現在はその準備期間とのことです。
これまでChatGPTをはじめとした文章生成、そしてDALL-E3をはじめとした画像生成はかなりの精度が出ていたけれど、動画はさすがに先でしょー、、なんて言ってたものが、Soraの誕生によって一気に進化を遂げてきました。

Soraの詳細
それでは公式ページの内容から現状の詳細について見ていきたいと思います。
内容を直訳してみた内容を見てみましょう!
基本事項
OpenAI
私たちは、AIに物理世界の動きを理解して模倣する方法を教え込んでいます。これは、実世界のインタラクションが必要な問題を解決するのを人々が助けるためのモデルを訓練することが目標です。
「Sora」という、私たちのテキストから動画を生成するモデルを紹介します。Soraは、視覚的な品質を保ちつつ、ユーザーのリクエストに忠実であることを維持しながら、最大1分間の動画を生成することができます。
ということで、まずは現状はまだ訓練段階ということを伝えているようです。
基本構造としてはテキストから動画を生成するスタイルで、最大1分間ということで、SNSや広告などの短尺のクリエイティブなら、結構これで代用できるのではないか、と感じるくらいのクオリティの動画が公式ページには載っていました。
検証中の内容
OpenAI
今日から、Soraがレッドチームの人たちに開放され、危害やリスクのある重要なエリアを評価するために利用できるようになります。また、クリエイティブな専門家にとって最も役立つモデルを開発するためのフィードバックを得る目的で、多数のビジュアルアーティスト、デザイナー、映画製作者にもアクセスを許可しています。
OpenAI外の人々と協力し、フィードバックを得るために、研究の進捗を早期に共有しています。そして、公衆にAIの能力がどのようなものか、どんな可能性があるのかを感じてもらうためです。
これまで画像生成でも問題になっていた、著作権などの問題に現在取り組んでいるようです。アーティストや映画製作者の方などから順次テスト利用されているようですね。
これらの方々のチェック・検証を行い、問題ないとなったら実際に一般開放される、という感じのようです。
生成される動画の内容
OpenAI
Soraは、複数のキャラクター、特定の動作タイプ、そして対象と背景の正確な詳細を含む複雑なシーンを生成することができます。このモデルは、ユーザーがプロンプトで求めたものだけでなく、それらが物理的な世界でどのように存在するかも理解しています。
これまで動画生成に関するハードルでもあった、複雑な動作や背景などの理解も結構進んでいるようですね。
プロンプトで求めたものだけでなく、現実の世界でどのような存在であるか、というところまで理解し、動画生成まで出来るというところは非常に興味深いですね。
これまでChatGPTなども含めて学習をすればより精度が高まる、という部分を考えれば、より学習量を増やすことが出来て、正確なプロンプトを作ることが出来ればかなり制度が高い動画を生成できるのでは、という可能性を感じさせる内容ですね。
Soraの現状の弱点
公式ページではどれだけのことが出来るか、と共に弱点の部分も語ってくれています。
OpenAI
現在のモデルには弱点があります。複雑なシーンの物理を正確にシミュレートすることに苦戦する場合があり、特定の原因と結果を理解できないことがあります。例えば、人がクッキーを一口食べた後、そのクッキーに噛み跡が残らないことがあります。
また、モデルはプロンプトの空間的な詳細を混同することもあります。例えば、左と右を混同したり、特定のカメラの軌道を追うような、時間をかけて起こるイベントの正確な説明に苦労することがあります。
ということで、ひとつ前の章で語っていたことの精度について詳細を伝えてくれており、旧来の動画生成AIよりは複雑な内容に関する生成は、大幅に改善されているが、やはり表現するのが難しい内容も一部あるようです。
ただ、これも前項でも書きましたが、より学習量を増やしていき、どれが求められていることと合致しているのか、ということを多く学習していくことにより、精度が高くなっていき、解消できるのは、という期待を抱かせてくれる内容でもあります。
またユーザーが初期にSoraを使用する場合には、これらのエラーを起こさず自分の求めた動画生成をしてもらうために、エラーを起こさないようなプロンプトを考えるのも一つ試行錯誤が必要なこととなってきそうですね。
研究内容のまとめ
OpenAI
Soraは、静的なノイズのように見えるビデオから始まり、多くのステップを経てノイズを取り除きながら徐々に変化させていくことでビデオを生成する拡散モデルです。
このモデルは、一度に完全なビデオを生成したり、生成したビデオを延長してより長くすることができます。多くのフレームを一度に予測することで、一時的に視界から消えたとしても、対象が同じであることを保証する難問を解決しました。
GPTモデルと同様に、Soraはトランスフォーマーアーキテクチャを使用し、優れたスケーリング性能を解き放ちます。
ビデオや画像を、GPTのトークンに似た小さなデータ単位であるパッチの集合として表現します。データの表現方法を統一することで、以前よりも幅広い視覚データに対して拡散トランスフォーマーを訓練することが可能になり、異なる期間、解像度、アスペクト比をカバーします。
Soraは、DALL·EやGPTモデルの過去の研究に基づいています。DALL·E 3からの再キャプション技術を使用し、視覚トレーニングデータに対して非常に詳細なキャプションを生成します。その結果、モデルは生成されたビデオでユーザーのテキスト指示により忠実に従うことができます。
テキスト指示だけからビデオを生成する能力に加えて、既存の静止画からビデオを生成し、画像の内容を正確にアニメーション化することができます。また、既存のビデオを延長したり、欠落しているフレームを埋めたりすることも可能です。技術レポートで詳しく学ぶことができます。
Soraは、現実世界を理解しシミュレートするモデルの基盤として機能し、私たちはそれがAGIを達成するための重要なマイルストーンになると信じています。
ここの項目は少し長かったので、内容を抜粋してみました。
メモ
- 自動で学習し、ノイズキャンセリングまでしてくれる
- 対象を認識し、別フレームでも同対象だと認識もしてくれる
- DALL-E3やChatGPTの研究も活用されている
- 上記により文字から動画生成への精度も高くなる
- 尺の延長や欠損したフレームを埋めるなども可能
と言ったのが気になった内容が書かれていたようです。
要は、とりあえずすごい!という感じですかね 笑
想定される活用方法
さて、ここからは想定される活用方法についても考えてみたいと思います。
活用法
- SNSやYouTubeショートの短尺動画
- 広告などの動画クリエイティブ
- 広報などへの活用
など様々な活用方法が考えられる感じですね。
これまで動画作成が出来なかった人でも、素材はSoraに作ってもらい、テキストなどを後乗せで行えれば立派な動画クリエイティブに!というような使い方も出来そうです。
またイメージ映像、みたいな感じであれば、プロンプトをしっかり作りこみ指示することが出来れば、結構なクオリティの動画がテキストから作成できる、という未来もそう遠くない感じがします。
既に動画が作れる人であれば、下地をSoraに作ってもらいそれを編集するだけ、という感じになれば、これまでかかっていた作成時間を大幅に短縮できるという活用法も考えられるでしょう。
といった感じで多くの可能性が

まとめ

ということで今回は2/16に発表された動画生成AI「Sora」について見てきました。
2024年2月現在での内容のまとめをしておきましょう。
ポイント
- Soraは文字から動画生成ができるOpenAI社製のAI
- 2024年2月現在は検証中でまだ一般利用は出来ないよう
- 学習により生成精度はどんどん上がりそう
- 動画に関するタスクも大幅に軽減できそう
といったところが現状のSoraに関するまとめと言ったところです。
何はともあれ、ChatGPTやGPTsで徐々に効率化が出てきた方々も、まだこれから生成AIを活用したいという方にとっても、文字テキストから動画生成が簡単にできる、となれば、また次元が変わるのではないかな、と個人的には思ったりしています。
とりあえず、早く試してみたい!というのが今回の感想でしょうか。実際に使うまでに情報を収集しながら、どのようなシーンや使い方でSoraを活用すれば良いのか、というのも考えておきたいおものですね。続報を待ちましょう。
百聞は一見に如かず
まずは公式ページで実際の動画をご覧になってください ↓
【Sora 公式ページ】
{kind=link}